1. Contributions
- A new nonlinear supervised multi-view learning method MvLE is proposed to perform the RGB-D human emotion recognition.
- Multi-hidden-layer out-of-sample network (MHON) is the out-of-sample extension of MvLE.
- As a new distance metric method, bag of neighbors (BON) can not only overcome the difference between views, but also introduce the category discriminant information.
- We introduced a new video-emotion RGB-D dataset and a new face-emotion RGB-D dataset to evaluate the proposed method.
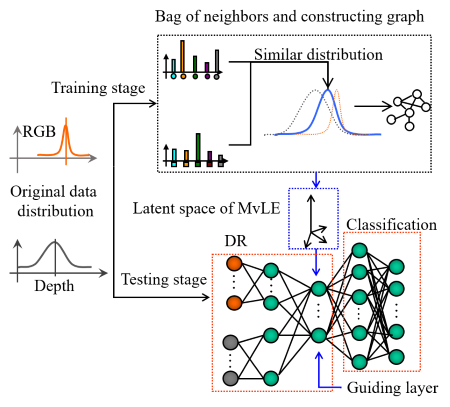
2. Motivations
- There are few nonlinear subspace learning methods proposed.
- Most of existing two-view learning methods are difficult to extend to multi-view.
- Label information is not utilized for the unsupervised multi-view learning methods.
- Most of supervised methods aim only at optimizing the correlation of classes or views.
- Most of existing human emotion dataset focus only on the RGB view.
3. Multi-view laplacian eigenmaps
3.1. Bag of Neighbors
As the distance between samples of different views are difficult to metric, we represent each sample with a bag of neighbors (BON) vector. Let \(BON_a = [x_1, x_2, \cdots, x_c]\) denotes the BON vector of sample \(a\), where \(x_t\) denotes the number of samples which are labeled as class \(t\) in the \(K\)-nearest neighbors of sample \(a\).
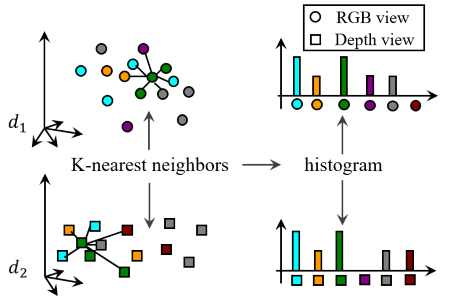
3.2. Weighted graph of all views
A weighted graph of all views is construct based on BON, which is composed by weighted graphs between each two views, indicating inter-view or intra-view similarity measures. Whether samples are connected or not depends on labels of they and their neighbors. Then the optimization target is formulated as:
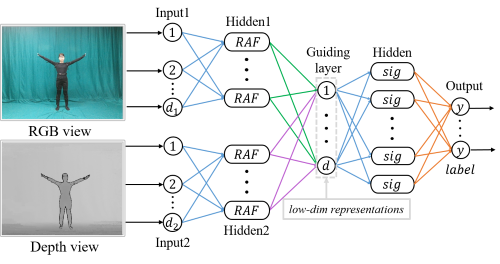
\[\begin{align}\nonumber \begin{split} \mathop{\min\limits_{Y}}\frac{1}{2}\sum_{a,b}\|y_a - y_b\|_2^2W_{ij}& = \mathop{\min\limits_{Y}}tr(Y^TLY) \\ s.t. \ Y^TDY &= I \\ D_{kk} = \sum_{j=1}^{n_i}{W_{jk}},&\ L=D-W \end{split} \end{align}\]3.3. Multi-hidden-layer Out-of-sample Network
MNON is the out-of-sample extension of MvLE. MHON is trained on the original distributions of RGB-D views and their labels. In the guiding layer of MHON, low-dimensional representations of training set is used as the leading information and feed forward.
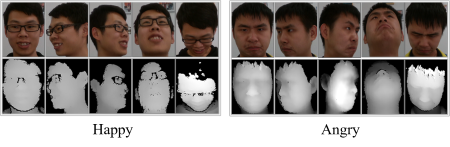
4. Two new datasets
4.1. RGB-D video-emotion dataset
The video-emotion dataset consists of over 4k clips of RGB videos and 4k clips of depth videos that are corresponding.

4.2. RGB-D face-emotion dataset
The face-emotion dataset includes about 1k RGB face emotion images and 1k depth face emotion images that are corresponding.
5. Evaluation
Experiments on the two RGB-D human emotion dataset indicate the effectiveness of MvLE.